Frontier Research
I like to understand how things work and use that understanding to build fun things. Sometimes, that means treehouses for my daughters. Sometimes, that means new AI models.
Neural Diversity Regularizes Hallucinations in Language Models
Link: https://arxiv.org/abs/2510.20690
Status: Accepted, Transactions in Machine Learning Research (2026)
What if the cause of AI hallucinations was noise? (Not lack of knowledge?)
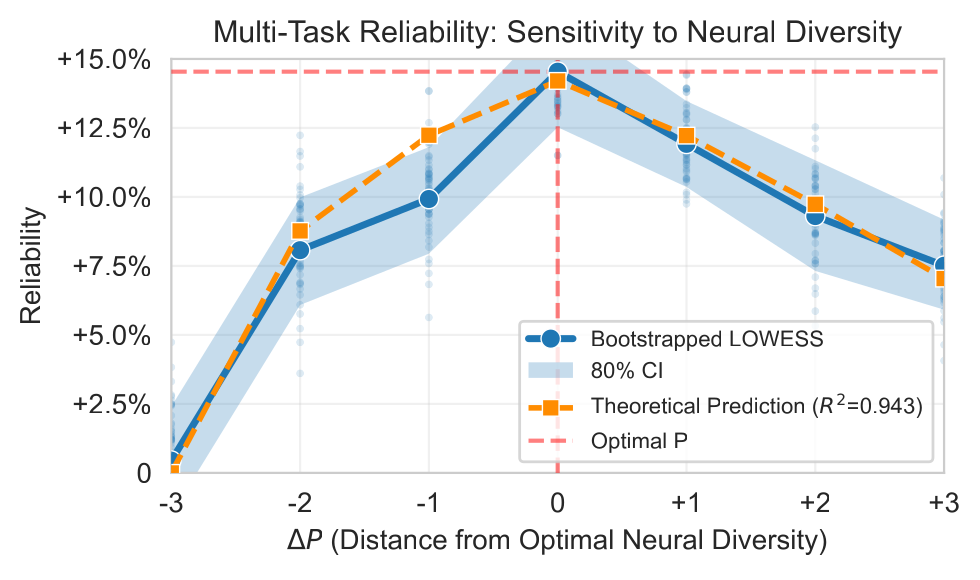
Markowitz won a Nobel for one idea: don’t hold assets that crash together. (Correlated risks.) Borrowing from portfolio theory, we re-interpret a model’s parallel reasoning lanes as a portfolio and find them badly under-diversified, so their errors line up instead of canceling. De-correlating them cuts hallucinations up to 25.6% at no cost to capability and the portfolio math predicts 94.3% of the variance we see.
Upshot: Alongside data and parameters, neural diversity is an orthogonal, third axis to build more reliable models.
Multi-Head Attention is a Multi-Player Game
Link: https://arxiv.org/abs/2602.00861
Status: Under review
Why does a model optimizing one goal still sabotage itself?
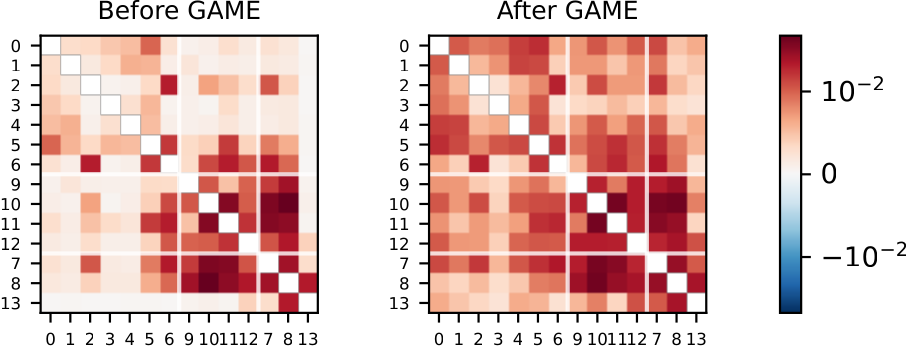
Because it’s not one mind. A transformer’s many attention heads run independently, coordinating and competing with each other in non-trivial ways — duplicated work, correlated mistakes — but we continue to train them as if it was a monolith.
Borrowing from game theory, we reframe gradient descent on cross-entropy loss as a game with multiple players, demonstrating that its price of anarchy explains redundant heads and hallucination. By gently taxing anarchy, we show that you can herd those selfish heads into more effective coalitions and improve reliability up to 18% without any loss of capability.
Upshot: Attention is all you need, but coordination is what you lack.
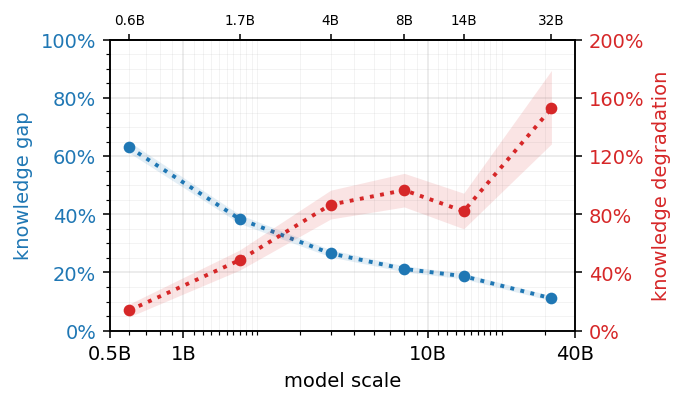
Reliability Inverse Scaling: Bigger Models Compound Mistakes Faster
Link: (forthcoming)
Status: Under review
We keep assuming bigger models will be trustworthier. This paper shows the opposite — reliability scales inversely.
As models get bigger, they get more fragile. Their answers start truer but go wrong faster — capability and reliability are separate dials, and scale spins them in opposite directions. As models scale, the knowledge gap shrinks by ~6×, yet the rate at which it degrades what it already knows grows by 11–39×. The culprit isn’t missing facts but a hidden risk: the model blurts out one low-odds word, treats its guess as settled fact, and builds on it — its self-doubt goes quiet while the real risk hides from detectors built to catch it. If you squeeze that one risk, hallucinations drop by 35-74%.
Upshot: Bigger models are more fragile.