Frontier Research
I like to understand how things work and use that to build fun things. Sometimes, that means treehouses for my daughters. Sometimes, that means new AI models.
In modern AI (over the past ~10 years), my work has mostly focused on four things: reliability, world models, human-AI augmentation and agents. Given the nature of my work (e.g. adversarial market-making at $100B/yr scale at Opendoor), most of it I couldn’t publish but it’s been fun publishing again as an indie researcher over the past ~6 months, during which I’ve published 3 papers (2 under review, 1 accepted at TMLR).
Reliability
Neural Diversity Regularizes Hallucinations in Language Models
Basic Question: What if LLM hallucinations were caused by noise (not lack of knowledge)?
Status: Accepted, Transactions in Machine Learning Research (2026)
Link: https://arxiv.org/abs/2510.20690
Although LLMs have demonstrated remarkable progress in gaining capability, LLM hallucination (especially without tool-calling) has been quite stubborn. Sometimes, if a problem seems surprisingly hard despite really smart people working on it, it’s because we’re asking the wrong question.
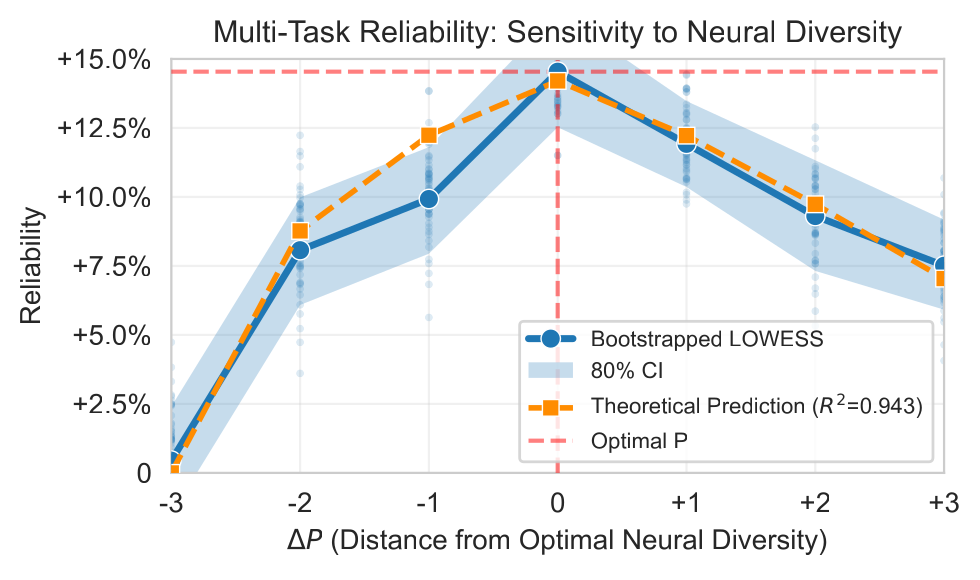
Borrowing from portfolio theory (tl;dr: diversifying risks reduces total risk), we re-interpret a model’s parallel reasoning lanes as a portfolio and find them badly under-diversified, so their errors line up instead of canceling. De-correlating them reduces hallucination up to 25.6% at no cost to capability and produces the first-ever provable bounds on hallucination, which predicts 94.3% of the real-world variance we see.
Upshot: Neural diversity is a third axis to improve model reliability, in addition to data and parameters.
Multi-Head Attention is a Multi-Player Game
Basic Question: What is the price of ignoring intra-model collaboration?
Status: Under Review
Link: https://arxiv.org/abs/2602.00861
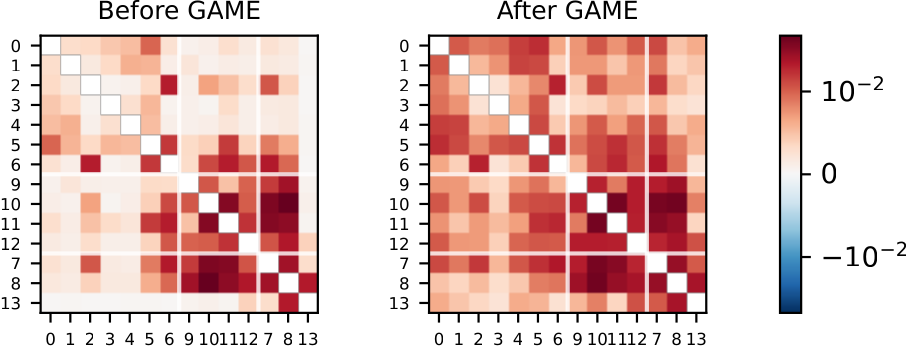
Modern transformer attention is internally multi-agent — heads compete and coordinate — yet we train it as if it were a monolithic optimizer.
Borrowing from algorithmic game theory (tl;dr: selfish players settle into equilibria that can be arbitrarily worse than the cooperative optimum), we show cross-entropy training induces an implicit game among heads and gradient descent lands on Nash equilibria with unpriced externalities. We (i) prove that the price of this anarchy manifests as head redundancy and hallucination and (ii) demonstrate that explicitly managing this anarchy reduces hallucination by up to 25.6% at zero knowledge cost.
Upshot: Attention is all you need, but coordination is what you lack.
Reliability Inverse Scaling: Bigger Models Compound Mistakes Faster
Basic Question: How does reliability scale?
Status: Under Review
Link: <forthcoming>
We keep assuming bigger models will be trustworthier. This paper shows the opposite — reliability scales inversely.
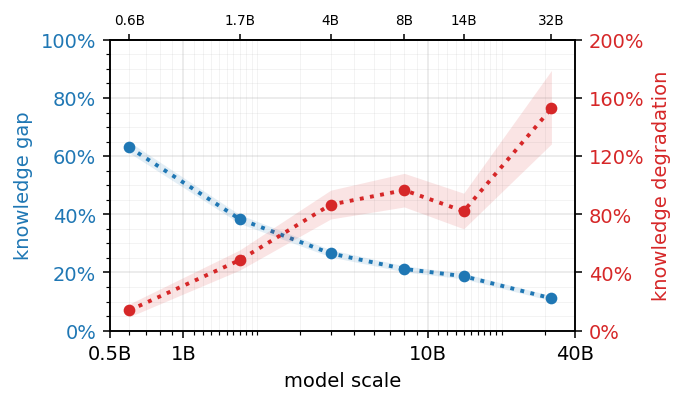
As models get bigger, they get more fragile. In long-form responses, their answers start truer but degrade faster — capability and reliability are separate dials and scale spins them in opposite directions. As models scale, the knowledge gap shrinks by ~6×, yet the rate at which answers degrade grows by 11–39×. The culprit a latent risk regime: the model blurts out one low-odds word, treats its guess as settled fact, and builds on it — its self-doubt goes quiet while the real risk hides from detectors built to catch it. If you squeeze down that risk, hallucinations drop by 35-74%.
Upshot: Bigger models are more fragile.
World Models
How do you make $100B in offers on O(million) homes in a minute or less? Opendoor fundamentally solved