Frontier Research
Neural Diversity Regularizes Hallucinations in Language Models
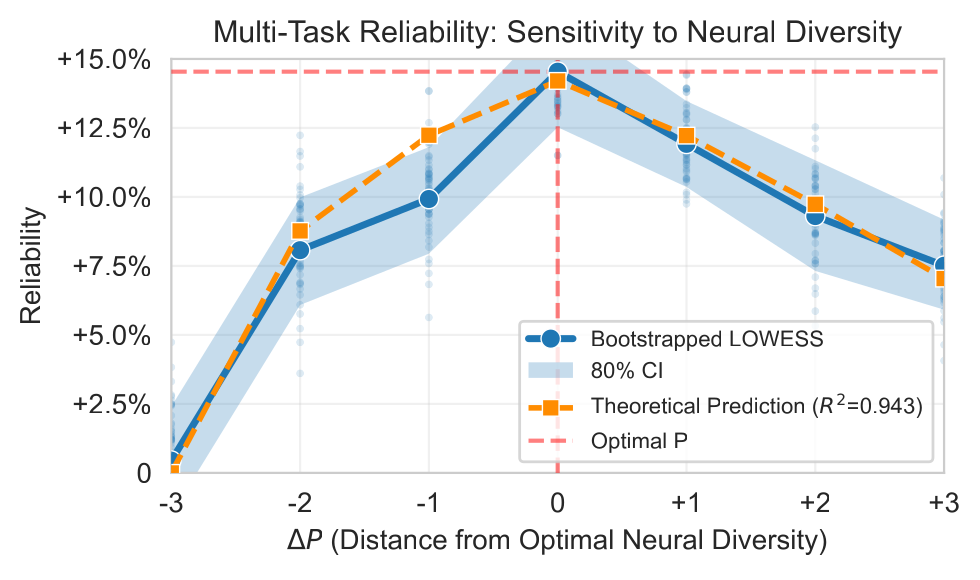
Why do language models still make things up, even as they get bigger? Part of the answer, this paper argues, is too little internal diversity: a model’s parallel “lanes” of reasoning end up echoing one another, so their mistakes line up instead of canceling out. Deliberately decorrelating those lanes — a method called ND-LoRA — cuts hallucinations by up to 25.6% (14.6% on average) with no loss in general ability, and a simple theory pins down the sweet spot well enough to explain 94.3% of the reliability differences we observe. The upshot: “neural diversity” is a third dial for building more reliable models, alongside more data and more parameters.
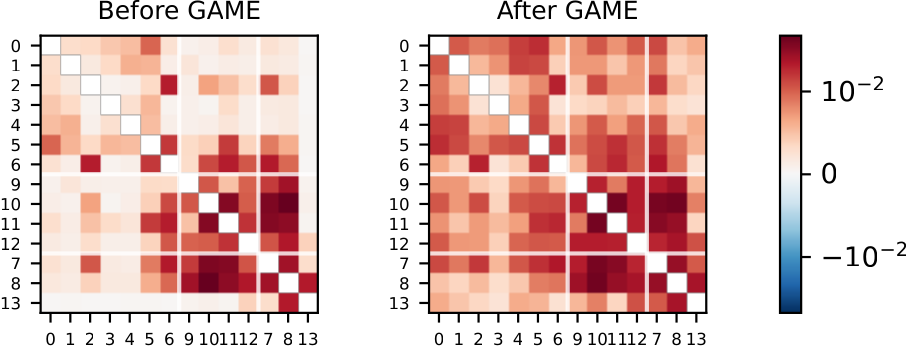
Multi-Head Attention is a Multi-Player Game
Inside every transformer, dozens of “attention heads” work in parallel — yet we train them as if they were a single mind rather than a team. This paper reframes them as players in a game, each chasing its own reward while quietly imposing costs on the rest (duplicated work, correlated mistakes). Borrowing the economist’s notion of a “price of anarchy,” it shows that how mathematically tangled the heads are predicts how much the model hallucinates. A regularizer that gently “taxes” that tangle — GAME-LoRA — nudges the heads into cooperative coalitions and trims hallucinations by up to 18% (8% on average) without sacrificing what the model knows.