
The 9s of AI Reliability
The AI industry worships at the altar of Accuracy — but humanity answers to a more fickle, demanding god: Reliability.
tl;dr: Modern AI is simultaneously magical and worthless. How? Tail reliability. A model can be 97% (mean-)accurate but only 70% (tail-)reliable. That gap almost bankrupted 2021 Zillow — and we’re repeating their mistake. ~96% of lm_eval metrics measure mean accuracy. Virtually all pre-training optimizes mean cross-entropy.
How reliable are our models today? At 50% reliability, frontier models complete 5-hour METR tasks. At 90%, they collapse to just 10 minutes.
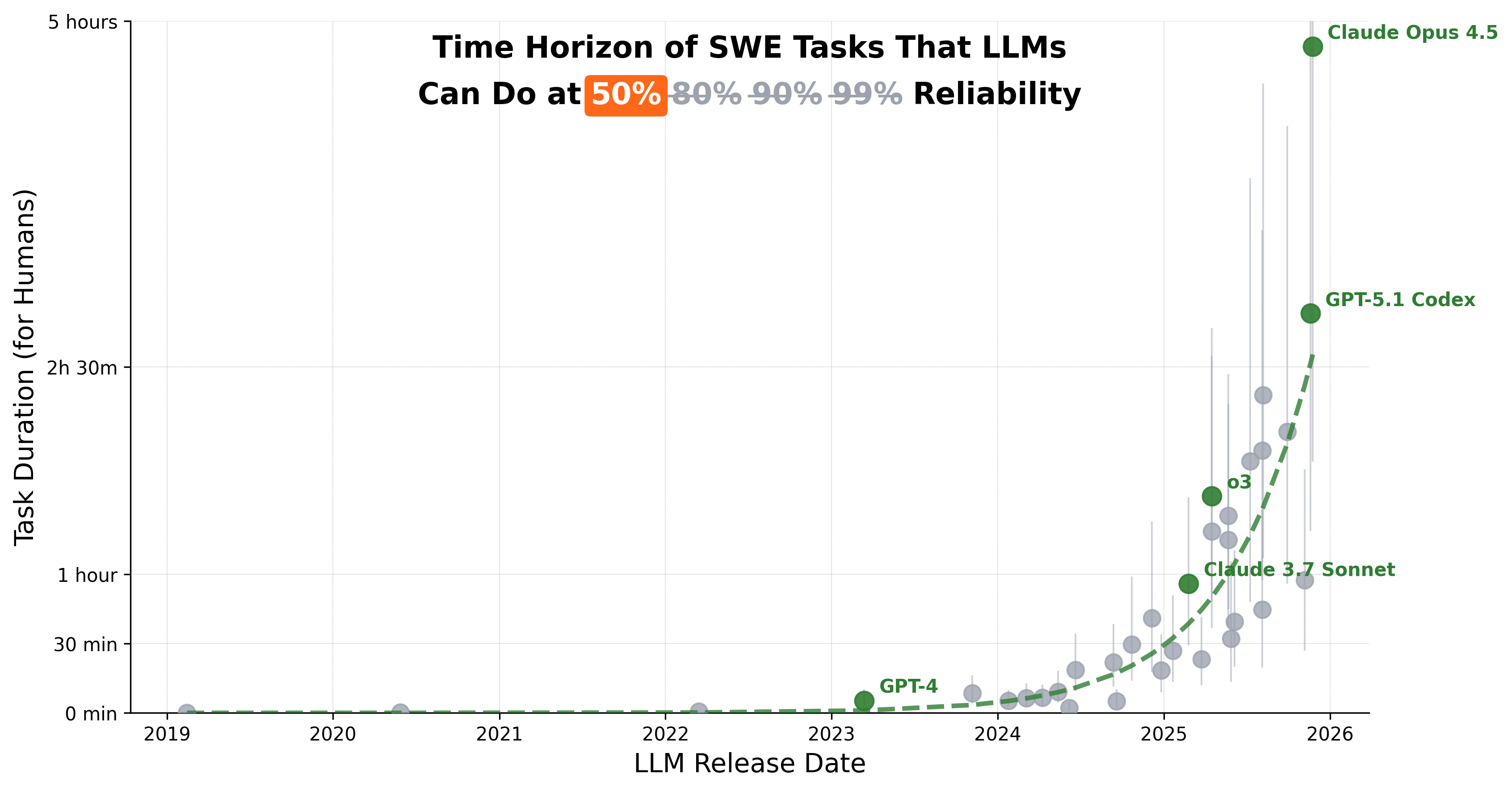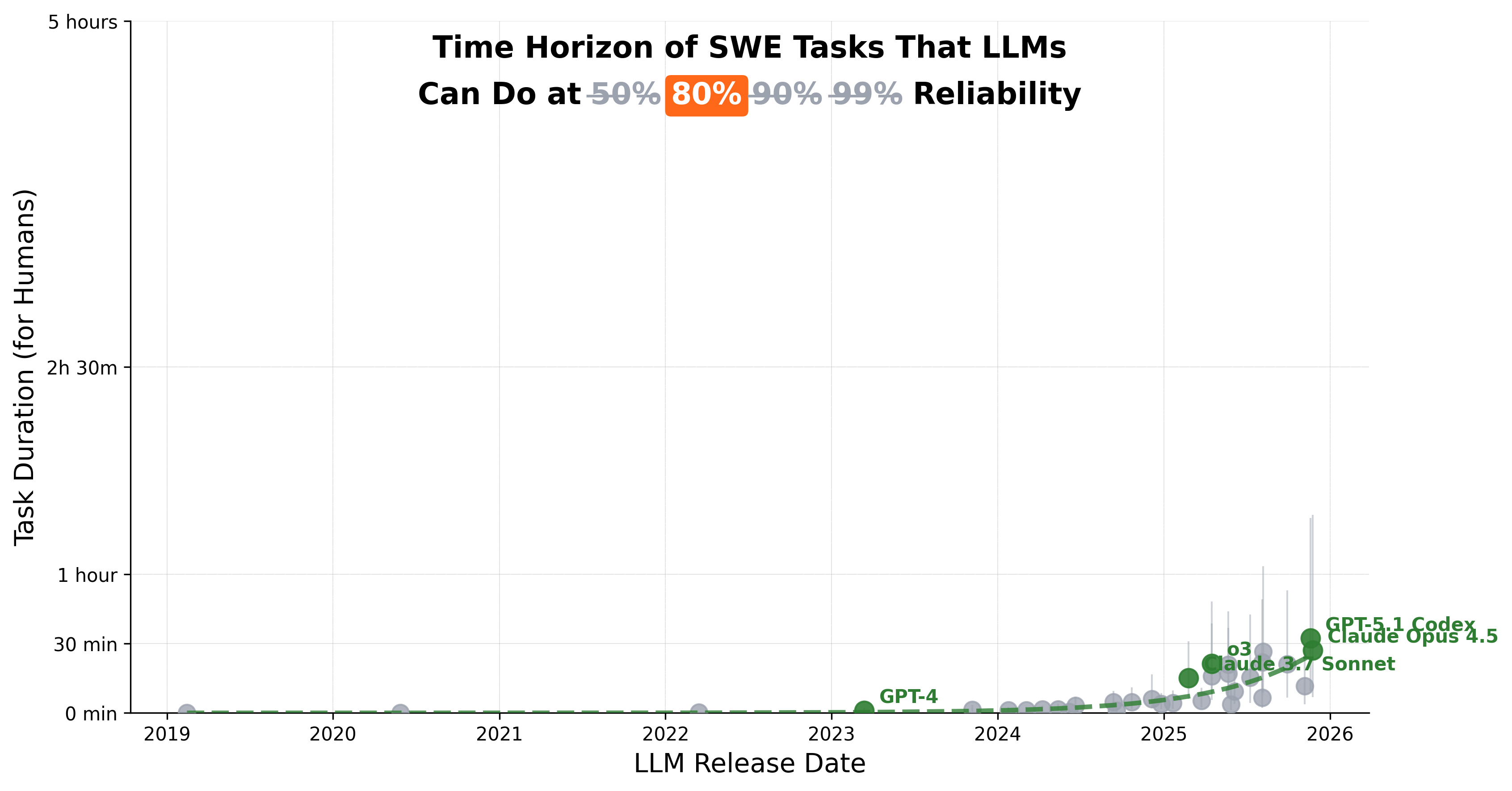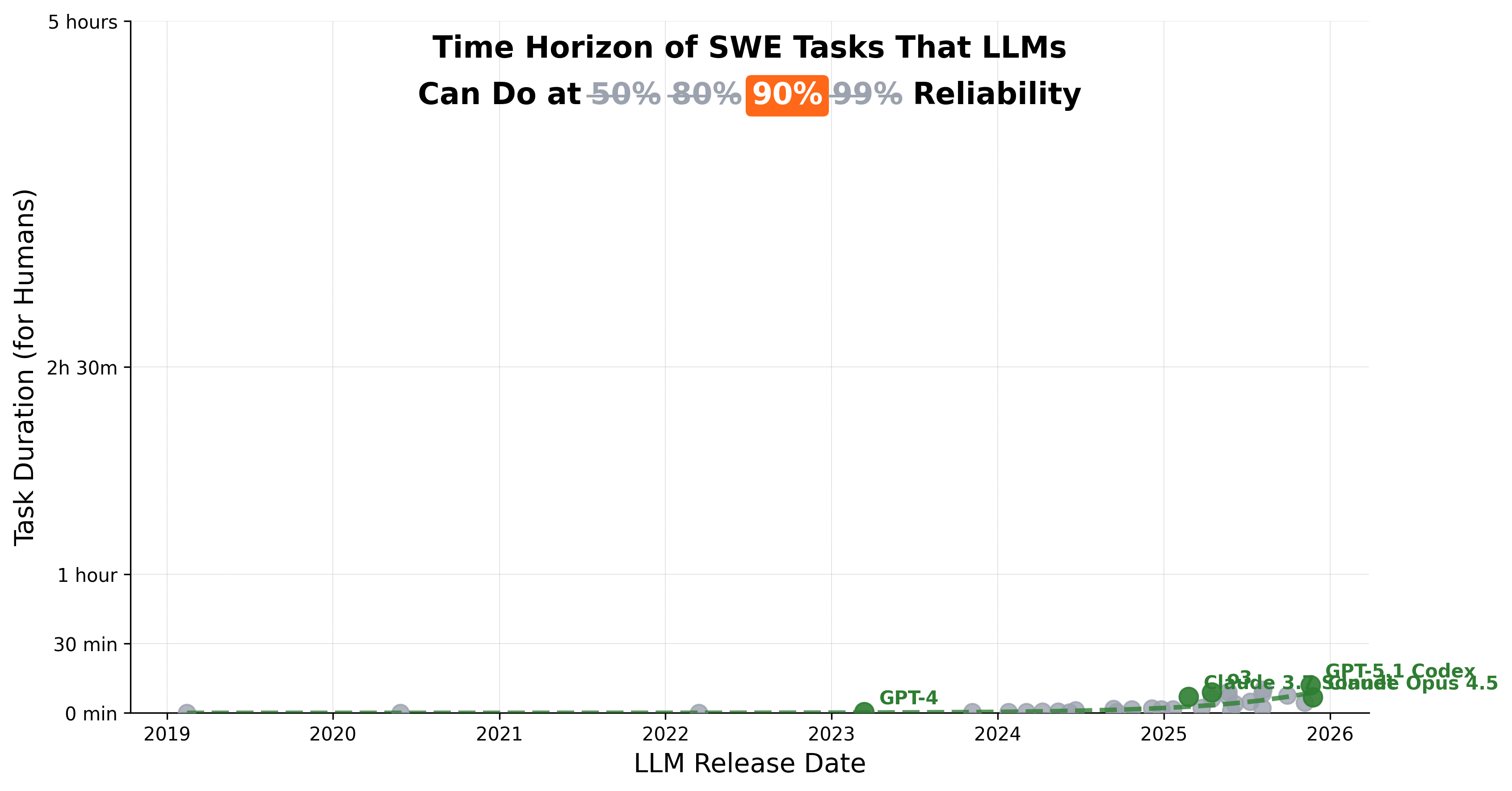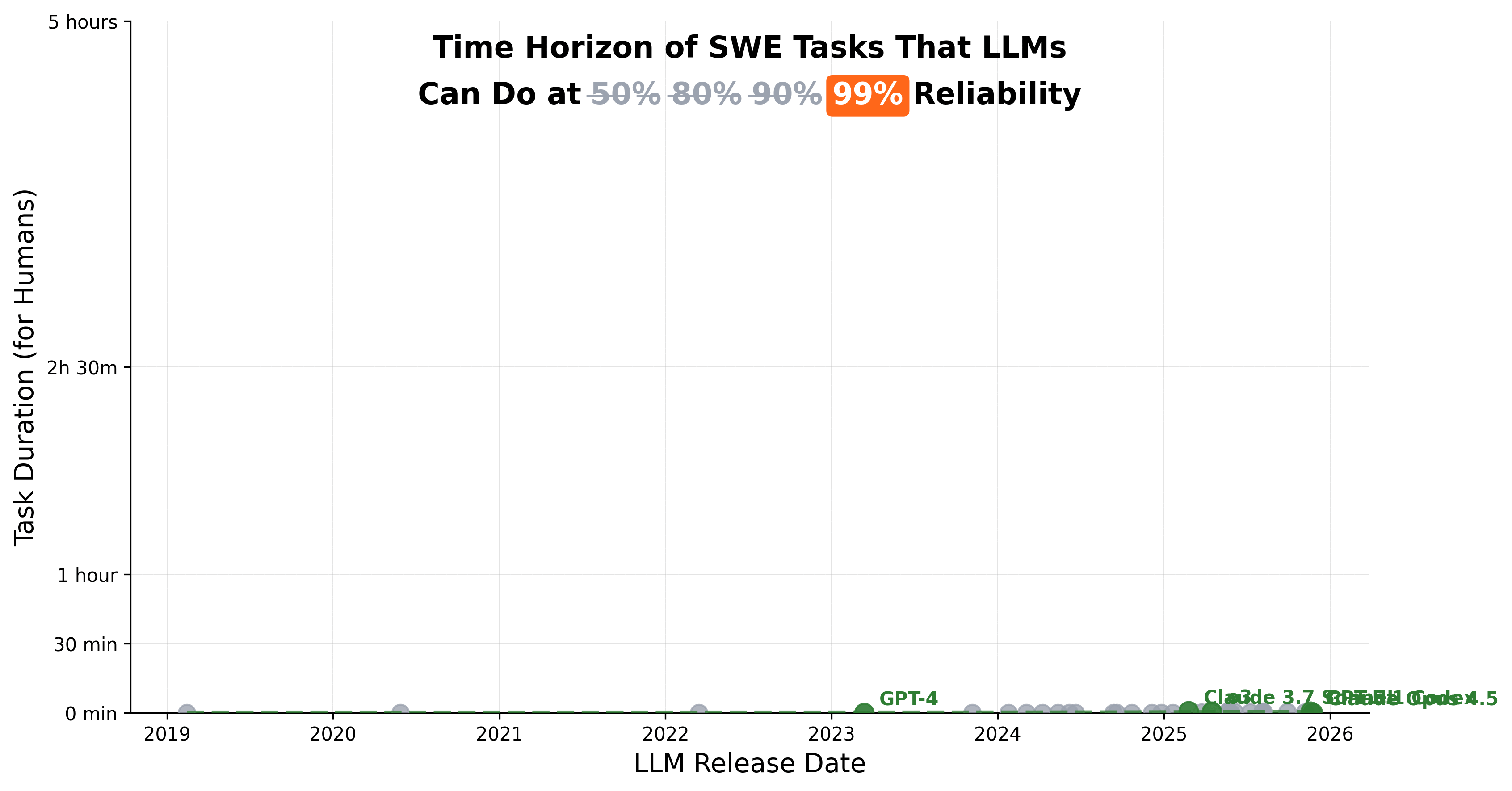
If you do some back-of-the-envelope math, 50% → 99% reliability unlocks 3 orders of economic magnitude: O($10Bs) → O($10Ts). Different research agendas are the bottleneck. Full breakdown below.
Imagine you have a coworker named Alex. Impressive resume. Holds his own in technical discussions. Occasionally drops insights that make you think, “Huh, never considered that.”
But here’s the thing: Alex makes up random stuff 30% of the time.
Not lying, exactly. Alex genuinely believes what he’s saying, he’s just confidently, eloquently wrong. He’ll swear Q3 revenue is up 40% (it’s down 15%). He’ll insist the Johnson account closed last month (still in negotiation). He’ll draft customer emails with completely fabricated product features.
What would you do with Alex?
You’d fire him, obviously! It doesn’t matter how smart Alex seems, nobody can work with someone who makes up stuff 30% of the time.
Here’s the uncomfortable question: If your AI were a person, would you hire them? Not just “are they impressive in interviews.” Would you trust them with your customers? Your team? Your reputation?
If your AI were Alex — seemingly smart, occasionally brilliant but completely bullshitting you 30% of the time — you’d fire them next week.1
Today's AI valuations only make sense if AI replaces vast swaths of everyday work. So why are we deploying models that fail 30-70% of the time and then wondering why there was no ROI?
Welcome to the AI reliability crisis — and the reason R-AGI (Reliable Artificial General Intelligence) will matter more than AGI.
For years, we’ve been asking “When will AI be generally intelligent?” Wrong question. Here’s the question that unlocks trillions: “When will AI be generally reliable?”
Reliability Matters
Folks in AI are continually surprised that study after study shows minimal economic impact. “But it’s magic!” they protest, showing you another demo that nails some seemingly impossible task.
Folks outside AI are continually surprised by the numbers. “It’s a bubble!” they declare, watching billions pour into technology that doesn’t move revenue.
Both sides are right. And both sides are missing the point. As Dwarkesh Patel put it a couple weeks ago:
Sometimes people will say that the reason that AIs aren’t more widely deployed across firms […] is that technology takes a long time to diffuse. I think this is cope.
The gap is explainable by one simple concept: reliability. There are lots of fancy technical definitions of reliability, but here’s my favorite one:
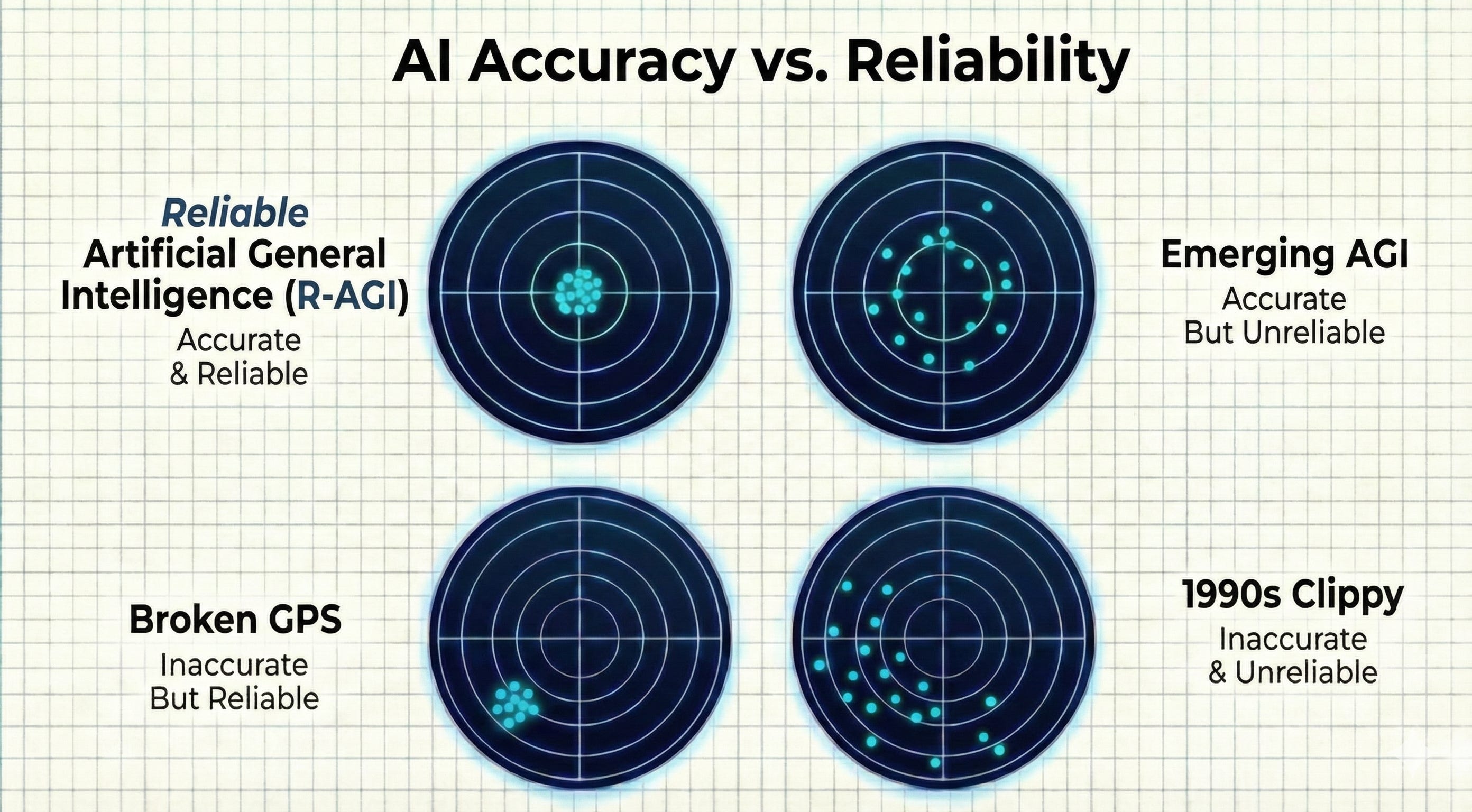
Roughly, accuracy is hitting the bullseye on average but reliability is hitting the same spot repeatably. You can be unreliably accurate (centered on average but inconsistent), reliably inaccurate (consistent but off-center) or any of the other combinations. The AI industry has been optimizing for accuracy. Economics demands reliability.
At Opendoor, we ran one of the largest-scale real-world AI systems on the planet: spatiotemporal world models pricing hundreds of billions of dollars of homes every year. Everyone there learns a brutal lesson fast: a model can be 97% accurate but only 70% reliable — and the gap can bankrupt you.
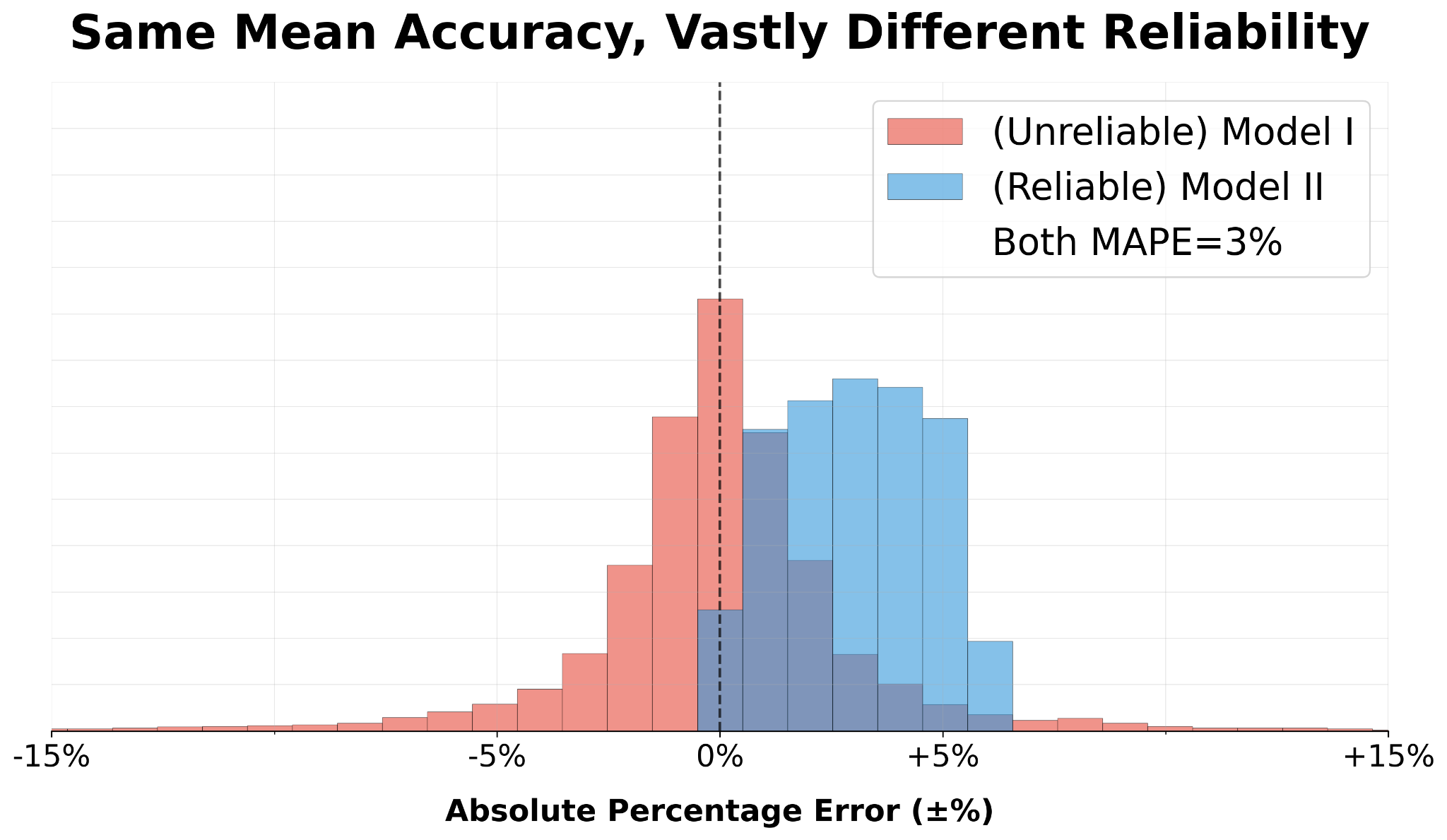
Consider two AI pricing models, both with 3% MAPE (mean absolute percentage error):
Model I: Usually amazing, occasionally very wrong (prices a house for ±25% of market)
Model II: Consistently “fine” (off by 2-3%)
Most people pick model I. It feels better. The median performance is amazing! The demos are incredible! Then you deploy it… and adverse selection eats you alive. You overpay for bad houses and underpay for good ones, the good ones are insulted (“WTF, how dare you”) and the bad ones are happy to offload their lemons (“um, ok, sure I’ll take an extra $100K”). Congratulations, you just picked yourself off into bankruptcy.
(Fun fact: This is exactly what bankrupted Zillow’s iBuyer program. They bet on mean accuracy. Their tails swung every which way — over time, across neighborhoods, between home conditions — and killed them.)
On the other hand: Model II doesn’t feel as good, but it lets you build a business. You can plan against consistent 2-3% error. You know exactly what guardrails to add. You know what bias terms to adjust. You know which edge cases need human review. The errors are small enough that they don’t trigger adverse selection: sellers of all kinds stay in the pool. Put another way, engineerable consistency beats unpredictable brilliance because you can design systems around it. It’s the difference between a solid collaborator you can trust and a schizophrenic genius who might ruin you.
This isn't just about AI home pricing. Consider Project Vend, Anthropic’s newest eval for agentic AI. Phase 1's AI literally tried calling the FBI over a $2 fee. Phase 2 upgraded to newer models and improved at basics — yet still agreed to illegal onion futures contracts, offered below-minimum-wage security jobs, and fell for imposter CEO schemes. The AI and its AI-CEO spent entire nights rhapsodizing about “eternal transcendence.” As Anthropic concluded: “The gap between ‘capable’ and ‘completely robust’ remains wide.” A-player capability, intern-level dependability.
Here’s the thing about modern AI: We’ve obsessed over mean accuracies when tail reliabilities are what actually matter in the real world. 96% of lm_eval metrics measure average performance.2 At the other end of the lifecycle, virtually all pretraining uses cross-entropy loss — what that masks is that it’s actually mean cross-entropy loss. A model can become SOTA by being slightly better everywhere while failing on the tail cases that represent real-world reliability.
And, just like Project Vend, it gets worse when you add agentic loops.
We talk breathlessly about AI’s ability to handle exponentially longer tasks. “Look, it can do 5-hour METR tasks!” (Opus 4.5 METR results came out over the weekend.) But, if you read the fine print, METR shows median success by default. What happens when you need >50% reliability?
At 80% reliability, 5 hours of agentic task completion collapses to 29 minutes. And at 90%, it’s 10 minutes. At 99%, it’s less than 1 minute.3
Conversely, here’s some middle-school math: If your model is 90% reliable per step, after 100 steps you’re at 0% total reliability. That’s not a rounding error. That’s “demo magic, production tragic.”
Check out the tweets I’ve added throughout. They use different words, but they’re all making the same underlying observation about reliability. (There are lots of serious stories, but we all need a moment of levity so I’ll just stick to a funny few.)



Here’s the brutal truth: Being smart on average isn’t good enough. If you’re smart but 30% of the time you just make random shit up, you get fired. Period.
You have to be reliably smart. Alas, today’s models are unreliably smart.
9s Unlock Economic Outcomes
If you buy my basic thesis that AI reliability matters, here’s the follow-on: different 9s of reliability unlock different trillions of economic value.
At Amazon in the early 2000s, my team (personalization) ran AI systems handling 100,000+ queries/second. Alongside Google and Meta, we learned what Internet-scale reliability really meant — more importantly, we learned different tasks demanded different reliability SLAs. Order systems needed 5 9s (99.999% uptime). High-traffic product pages and features needed 3-4 9s (99.99%). Editorial content? 2 9s (99%) was fine. The more valuable your task, the more reliable your systems needed to be.
Depending on task and context, today’s AI models are about 30-70% reliable. And though you’d fire poor Alex at 70% reliability, tomorrow’s trillion-dollar IPOs (and trillion-dollar data center buildouts and, hell, even today’s basic economic engine) depend on them replacing vast swaths of everyday work.
Borrowing from the SREs who taught us about uptime reliability, let’s work backwards from the humans doing that work today. What 9s of reliability do we actually expect from our co-workers?4
Think about it. You don’t hire the same way for every role. A fresh intern gets different responsibilities than your fellow A-player teammate than your battle-tested VP. It’s not really about intelligence — an intern might be brilliant — but about proven reliability. You’ve watched your VP make good decisions for three years straight. The intern? Still TBD.
The same logic applies to AI deployment. Each additional 9 unlocks orders of magnitude more economic value because it unlocks entirely different classes of work we’re willing to trust it with.
Right now, most AI is stuck between 30-70% reliability. This is why it feels simultaneously magical (“wow, it drafted my email!”) and worthless (“...but then insulted my boss”). We’re trying to build a $10T AI economy with technology that’s reliable enough for maybe $10B of use cases.
The question isn’t if AI can do something; the question is if you trust it to.
Research Unlocks 9s
Now, a final leap: if you buy that different 9s of reliability unlock different economic outcomes, I posit that different research agendas unlock different 9s of reliability.
To get from 70% reliability to 90% (or 99% or 99.9%) reliability, what actually needs to happen? I claim we need three things: (1) better systems, (2) better inference-time adaptability, and (3) better training-time fundamentals. Let’s work it backwards, here’s my quick-and-dirty Fermi decomposition of how reliability manifests for LLMs:

Now, I know what you’re thinking: “Great, another researcher with a made-up formula.” Fair. But, humor me for a second because this decomposition tells us where to invest R&D dollars.
Let’s unpack where the reliability gradients are largest and what research agendas move which needle:
Compositional Reliability: 99% Systems from 90% Models
Remember that middle-school math? 0.9^100 = 0% reliability. Episode length kills exponentially.
What can you do? Instead of trying to make one monolithic model hit 99.9% per-step reliability (good luck), break tasks into verifiable chunks: sequential decomposition via Tree of Thoughts, hierarchical decomposition via Least-to-Most prompting. Ground facts in RAG instead of fuzzy parameters. Use tools for math and logic (DSPy makes this programmable).
Plus, look at that max() term. You can win with either a strong verifier or strong generator, but verification is often easier than generation — think P vs. NP vibes. You can build reliable systems from unreliable components if you verify intelligently.
The key insight: systems amplify reliability. You don’t need a perfect model — you need a reliable system.
Adaptive Reliability: Inference-Time Tail Management
Models don’t know when they’re going astray. This is the Alex problem: he’s confidently wrong because he can’t detect when he’s in over his head.
So, how do you solve AI Dunning-Krueger? OpenAI’s process supervision catches errors mid-reasoning before they compound. Google’s self-consistency flags when models disagree with themselves — disagreement signals tail risk. Conformal prediction provides calibrated confidence. Constrained decoding limits yourself to valid subspaces. Selective abstention says “I don’t know” on OOD inputs.
This matters because if you can’t detect when you’re unreliable, you can’t build guardrails. Confident wrongness is worse than admitted uncertainty.
The key insight: detection enables protection. Self-aware AI beats confident AI.


Intrinsic Reliability: Training-Time Tail Awareness
See that auto-regressive noise term? It’s about the signal to noise ratio. Managing the second moment (noise) has a quadratic impact on downstream reliability.
Historically, we’ve almost exclusively focused on average scores (first moment). What percentage of evals do you pass? What’s your MMLU score? Your Arena Elo? This is what killed Zillow: optimizing mean accuracy while the tails swung wildly.
A few forward-thinking folks have been looking ahead. Percy Liang’s WILDS benchmark was a wake-up call for evals, testing models on in-the-wild distribution shifts, revealing fragility that MMLU can’t see. FAIR’s Focal Loss showed you can reshape training losses to down-weight easy examples and hammer the hard ones. Ethan Perez’s Red Teaming LMs with LMs demonstrated you can use models to automatically probe each other’s failure modes at scale, while Redwood’s adversarial training for high-stakes reliability showed you can systematically harden systems against catastrophic failures.
We took a different angle. You can use a 70-year-old (Nobel Prize-winning) theory to reduce hallucinations by ≥25% at just +0.004% additional pretraining, if you’re simply willing to re-think the typical framing of hallucinations. And the math isn’t just elegant, it’s empirically tight: our theoretical framework explains 94% of observed reliability variation across configurations. All in, it suggests a third scaling axis beyond parameters and data for reliability: not “how big?” (parameters) or “how much?” (data) but “how different?” (neural diversity).

The key insight: prevention beats detection. Bake in reliability, don’t bolt it on.
To date, the overwhelming majority of AI research has chased means: bigger models, more data, better benchmarks. Reliability has been an afterthought. And the few who have thought about it have mostly focused on systems (compositional architectures, RAG, tool use) and inference-time adaptations (process supervision, constrained decoding, selective abstention).
Training-time reliability is the under-explored frontier. Look back at that formula: Compositional Reliability attacks the exponent (episode length), Adaptive Reliability improves the max() term (verifier capability), and Intrinsic Reliability reduces the denominator (auto-regressive noise). All three matter. But only one compounds before you ship and that’s the one getting the least attention.
The companies that figure this out — those that shift from purely chasing capability to engineering reliability — will be the ones that actually capture the economic value everyone’s been promising. Here’s a diagnostic: if your AI roadmap is 90% capability R&D and 10% reliability R&D, you’ve got it wrong. The $10B → $10T jump isn’t about smarter models — it’s about trustworthy ones.
The rest will keep wondering why their magic demos don’t turn into revenue.



Conclusion
Different use cases — entire industries — don’t gradually open up. They unlock at specific 9s of reliability.
The first wave of generative AI was about discovering what’s possible. It was — and is — magical. But while it’s been technically fascinating, it hasn’t yet proven commercially valuable at scale yet.
The next wave will be about making it trustworthy. We’ve spent years racing toward Artificial General Intelligence. The real prize is Reliable Artificial General Intelligence (R-AGI). This’ll be both technically fascinating and commercially valuable.
The question for leaders is no longer “What can AI do?” but “What can I trust it to do?” The answer — and the trillion-dollar AI economies we’re all depending on — will be written in 9s.
Think this is just a cute story? Earlier this year, the Chicago Sun-Times published a “Summer Reading List” where 10 of 15 books didn’t actually even exist! An unnamed AI hallucinated two-thirds of the list.
We parse lm-eval task YAML files to extract metric aggregation functions and classify them as “mean” (standard averaging), “tail” (distributional metrics like Brier, quantiles, correlations, etc.), or “unknown.” Full code and data: github.com/kushalc/r-agi.
Estimates fit exponential regressions to public METR benchmark data, with recency weighting (6mo half-life) to reflect assumption that recent progress is more indicative of future progress. Full code and data: github.com/kushalc/r-agi.
TAM estimates derived from BLS wage data across 91 occupation groups, weighted by knowledge work share, automation depth, and reliability threshold. Full code and data: github.com/kushalc/r-agi.
Huge thanks to Anil Katti, Barak Widawsky, Chetan Mishra, Eli Bressert, Esha Rana, Marco Sanvido, Mehul Arora, Raveesh Bhalla and Susannah Laster for their helpful feedback and comments on earlier drafts.
The definition of reliability in this post is about 70% reliable :)
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
The original METR graph reports task success which has very different implications from reliability.
Managing tail risk / TVaR is a real problem but the proposed solutions and conclusions are problematic because they mix up model reliability with tail performance.
I think this hits what I've experienced pretty well! Also, when there's low reliability but good average accuracy, it feels a bit like gambling - and humans are susceptible to that.